随着Raft一致性算法论文的发表,该协议在分布式领域的应用越来越广泛,大有取代Paxos协议之势。
Raft概述
- Raft强调的是易懂(Understandability),在做技术决策和选型的时候,易于理解是非常重要的
- Raft算法能够给出实现系统的确定性,能够给出每个技术细节的清晰界定与描述
Raft使用了分而治之的思想把算法流程分为三个子问题:选举(Leader election)、日志复制(Log replication)、**安全性(Safety)**三个子问题。
Raft流程
- Raft开始时在集群中选举出Leader负责日志复制的管理;
- Leader接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader负责保证其他节点与他的日志同步;
- 当Leader宕掉后集群其他节点会发起选举选出新的Leader;
可以看到Raft采用的是Master-Slave模式,这在一定程度上简化了一致性维护的问题,清晰的看到各个系统所处的状态。
Raft详解
角色
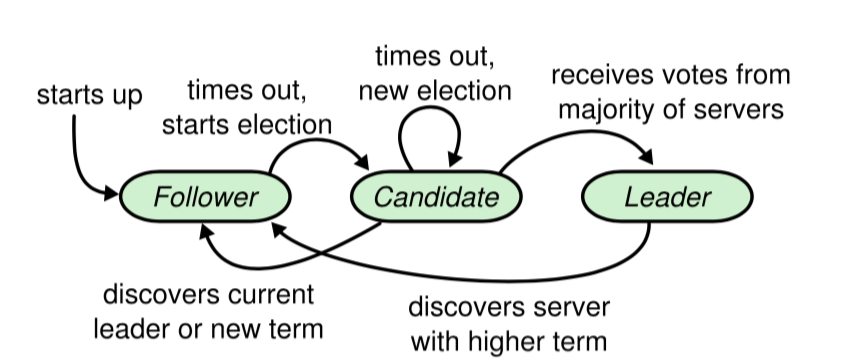
Raft把集群中的节点分为三种状态:Leader、Follower、Candidate。Raft运行时提供服务的时候只存在Leader与Follower两种状态;即Candidate是转换的中间状态。
- Leader(领导者):负责日志的同步管理,处理来自客户端的请求,与Follower保持这heartBeat的联系;
- Follower(追随者):刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应Candidate的请求,把请求到Follower的事务转发给Leader;
- Candidate(候选者):负责选举投票,Raft刚启动时由一个节点从Follower转为Candidate发起选举,选举出Leader后从Candidate转为Leader状态;
三者的转换关系及转换条件如下所示:
Term
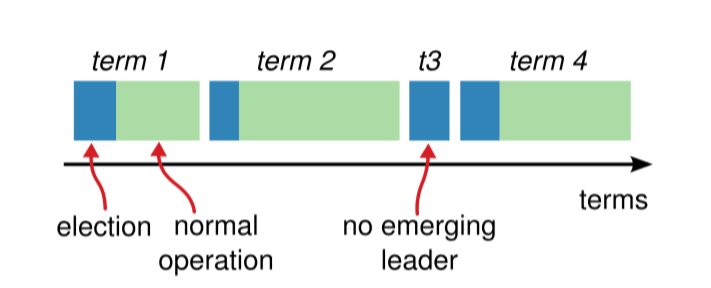
在Raft中使用了一个可以理解为周期(第几届、任期)的概念,用Term作为一个周期,每个Term都是一个连续递增的编号,每一轮选举都是一个Term周期,在一个Term中只能产生一个Leader;先简单描述下Term的变化流程:Raft开始时所有Follower的Term为1,其中一个Follower逻辑时钟到期后转换为Candidate,Term加1这是Term为2(任期),然后开始选举,这时候有几种情况会使Term发生改变:
- 如果当前Term为2的任期内没有选举出Leader或出现异常,则Term递增,开始新一任期选举
- 当这轮Term为2的周期选举出Leader后,过后Leader宕掉了,然后其他Follower转为Candidate,Term递增,开始新一任期选举
- 当Leader或Candidate发现自己的Term比别的Follower小时Leader或Candidate将转为Follower,Term递增
- 当Follower的Term比别的Term小时Follower也将更新Term保持与其他Follower一致;
可以说每次Term的递增都将发生新一轮的选举,Raft保证一个Term只有一个Leader,在Raft正常运转中所有的节点的Term都是一致的,如果节点不发生故障一个Term(任期)会一直保持下去,当某节点收到的请求中Term比当前Term小时则拒绝该请求。
选举
Raft的选举由定时器来触发,每个节点的选举定时器时间都是不一样的,开始时状态都为Follower某个节点定时器触发选举后Term递增,状态由Follower转为Candidate,向其他节点发起RequestVote RPC请求,这时候有三种可能的情况发生:
-
赢得本次选举
如果接收到大都输其他节点的投票,则赢得选举成为领导者,然后定时向其他服务器发送RPC心跳维护其Leader地位。
-
另一个服务器S宣称并确认自己是新的领导者
如果该Candidate收到服务器S的RPC,且Term编号大于Candidate自身编号,则自己转为Follower,否则拒绝承认S为新领导者并继续维持自身的Candidate状态。
-
经过一定时间仍然没有新领导者产生
由于同一时间有多个Follower转为Candidate状态,导致选票分流,所以没能得到多数选票。此时Candidate增加自身Term编号进入新一轮选举。
日志复制
**日志复制(Log Replication)**主要作用是用于保证节点的一致性,这阶段所做的操作也是为了保证一致性与高可用性;当Leader选举出来后便开始负责客户端的请求,所有事务(更新操作)请求都必须先经过Leader处理。
要保证节点的一致性就要保证每个节点都按顺序执行相同的操作序列,日志复制(Log Replication)就是为了保证执行相同的操作序列所做的工作;
- 在Raft中当接收到客户端的日志(事务请求)后先把该日志追加到本地的Log中;
- 然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日志后记录日志然后向Leader发送ACK;
- 当Leader收到大多数Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端;
- 并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中;
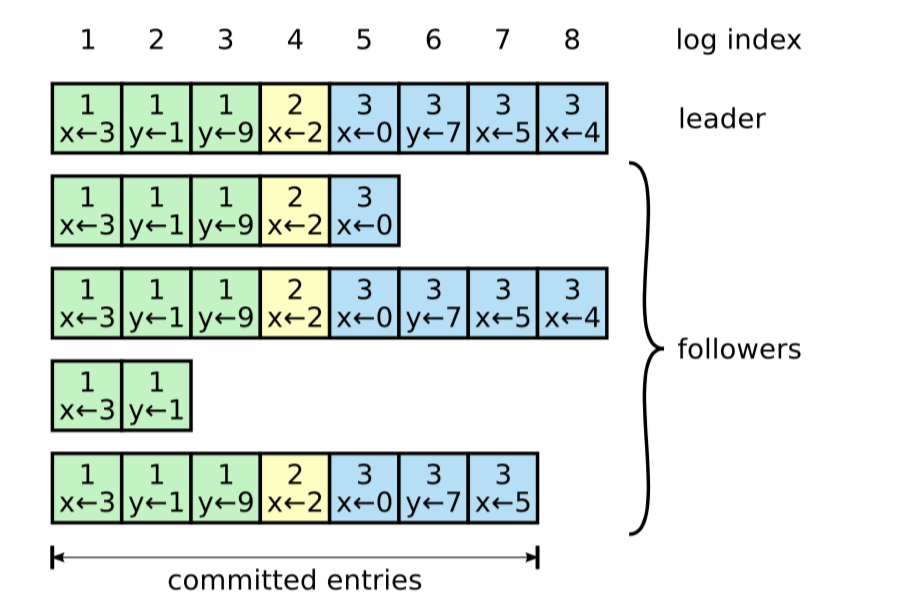
上图展示了每个Logs的组织结构。这些log entry都是从Leader中获取,其中每个log entry存储了一个状态机命令和任期号,且每个log entry包含整型的索引来确定在log中的位置。
安全性
安全性是用于保证每个节点都执行相同序列的安全机制,如当某个Follower在当前Leader commit Log时变得不可用了,稍后可能该Follower又会被选举为Leader,这时新Leader可能会用新的Log覆盖先前已committed的Log,这就是导致不同的节点执行不同序列。Safety就是用于保证选举出来的Leader一定包含先前commited Log的机制。
- 必须要比大部分其它候选者的log新,才有机会成为leader, 这个是只有拥有所有commit日志,才有可能被选为leader的充分非必要条件。在实现的时候,保证选举Leader满足前者条件,即:当请求投票的该Candidate的Term较大或Term相同Index更大则投票,否则拒绝该请求。 (限制了哪些服务器可以被选举为Leader)
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries.
- 对于新领导者而言,只有它自己已经提交过当前Term的操作命令才被认为是真正的提交(限制了哪些操作命令的提交可被认为真正的提交)
Only log entries from the leader’s current term are committed by counting replicas.