本篇较为深入的讲述了PHP的Opcode缓存原理。简要分析了PHP的脚本跟踪与分析技术。
opcode缓存
解释器 V.S. 编译器
如今Web开发人员在写脚本语言时都有很多的选择,PHP、Ruby、Python等,它们属于解释型语言。它们编写的动态语言都需要依赖响应的解释器来运行,那解释型语言到底与编译型语言(C/C++、JAVA等)有啥区别呢?
- 解释:解释器完成对脚本代码的分析,将它们生成可以直接运行的中间代码(操作码,Operator Code, opcode)。即从程序代码到中间代码的过程。
- 编译:编译器将程序代码生成中间代码。
上面两个定义貌似是一样的。是的,原理上编译和解释是相似的,都包括词法分析、语法分析、语义分析等。但是有个本质的不同在于:
- 解释器在生成中间代码后便可以直接运行它,所以运行时控制权在编译器
- 编译器则将中间代码进一步优化,生成可以直接运行的目标程序,但不执行它,所以控制权在目标程序,与编译器就没有任何关系了
正是因为解释器每次运行的时候都将脚本代码作为输入源分析,所以它的数据结构能够动态的改变,这使得解释型语言具备了很多丰富的动态特性,在开发和调试中有很多优势。但是相应的,其性能比不上编译型语言。
什么是opcode
PHP解释器的核心引擎是Zend Engine。那么对于 1+1这个简单的脚本,Zend引擎生成的opcode会是什么呢?
我们需要安装PHP的Parsekit扩展,来查看任何PHP文件或者代码段的opcode。直接进行如下调用:
php -r "var_dump(parsekit_compile_string('print 1+1;'));"
我们看主要涉及到的opcode部分:
["opcodes"]=>
array(4) {
[0]=>
array(8) {
["address"]=>
int(107095044)
["opcode"]=>
int(1)
["opcode_name"]=>
string(8) "ZEND_ADD"
["flags"]=>
int(197378)
["result"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(0)
}
["op1"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&int(1)
}
["op2"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&int(1)
}
["lineno"]=>
int(1)
}
[1]=>
array(7) {
["address"]=>
int(107095164)
["opcode"]=>
int(41)
["opcode_name"]=>
string(10) "ZEND_PRINT"
["flags"]=>
int(770)
["result"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(1)
}
["op1"]=>
array(3) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(0)
}
["lineno"]=>
int(1)
}
[2]=>
array(7) {
["address"]=>
int(107095284)
["opcode"]=>
int(70)
["opcode_name"]=>
string(9) "ZEND_FREE"
["flags"]=>
int(271104)
["op1"]=>
array(4) {
["type"]=>
int(2)
["type_name"]=>
string(10) "IS_TMP_VAR"
["var"]=>
int(1)
["EA.type"]=>
int(0)
}
["op2"]=>
array(3) {
["type"]=>
int(8)
["type_name"]=>
string(9) "IS_UNUSED"
["opline_num"]=>
string(1) "0"
}
["lineno"]=>
int(1)
}
[3]=>
array(7) {
["address"]=>
int(107095404)
["opcode"]=>
int(62)
["opcode_name"]=>
string(11) "ZEND_RETURN"
["flags"]=>
int(16777984)
["op1"]=>
array(3) {
["type"]=>
int(1)
["type_name"]=>
string(8) "IS_CONST"
["constant"]=>
&NULL
}
["extended_value"]=>
int(0)
["lineno"]=>
int(1)
}
}
似乎有些多,但是仔细观察,会发现在opcodes数组中,共有4条操作:
| opcode | opcode_name | op 1 | op 2 | op 3 |
|---|---|---|---|---|
| 1 | ZEND_ADD | IS_CONST(1) | IS_CONST(1) | IS_TMP_VAR |
| 41 | ZEND_PRINT | IS_TMP_VAR | ||
| 70 | ZEND_FREE | IS_TMP_VAR | IS_UNUSED | |
| 62 | ZEND_RETURN | IS_CONST(NULL) |
通过上面的分析,似曾相识的感觉,仿佛和汇编代码类似。的确,Zend核心引擎正式沿用了类似汇编语言的操作码形式(三地址码)。表格中四个运算符,分别对应四种运算形式:
result = op1 op op2
result = op op1
op1 op op2
op op1
三地址码生成目标容易就非常容易了。只需要将抽象的操作指令(如上面的ZEND_ADD)翻译成底层的操作指令即可。同样,解释器维护抽象层面的操作码,也是其跨平台运行的重要基础。
生成opcode
Zend引擎执行PHP脚本时,会经过如下四个步骤:
1. Scanning(Lexing) ,将PHP代码转换为语言片段(Tokens)
2. Parsing, 将Tokens转换成简单而有意义的表达式
3. Compilation, 将表达式编译成Opocdes
4. Execution, 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能
第一步,词法分析,解释器需要对所有单词进行分类,并给它们打上标记(token)。 我们可以在PHP源码的Zend目录中找到PHP解释器的词法分析文件,其中就有print对应的token为T_PRINT:
Zend/zend_language_scanner.l
<ST_IN_SCRIPTING>"print" {
return T_PRINT;
}
第二步,语法分析,当词法分析通过后,将进入语法分析:
Zend/zend_language_parse.y
T_PRINT expr { zend_do_print(&$$, &$2 TSRMLS_CC); }
语法分析器将T_RPINT标记以及上下文替换成了zend_do_print()函数
第三步,编译, 下面的函数实现了到opcode的转换,它设置了opcode指令以及op1的数据。
void zend_do_print(znode *result, const znode *arg TSRMLS_DC) /* {{{ */
{
zend_op *opline = get_next_op(CG(active_op_array) TSRMLS_CC);
opline->result.op_type = IS_TMP_VAR;
opline->result.u.var = get_temporary_variable(CG(active_op_array));
opline->opcode = ZEND_PRINT;
opline->op1 = *arg;
SET_UNUSED(opline->op2);
*result = opline->result;
}
第四步,执行, 依次执行Opcodes。
避免重复编译
从前面的opcode生成过程看,我们基本能知道为啥要引入opcode缓存了。
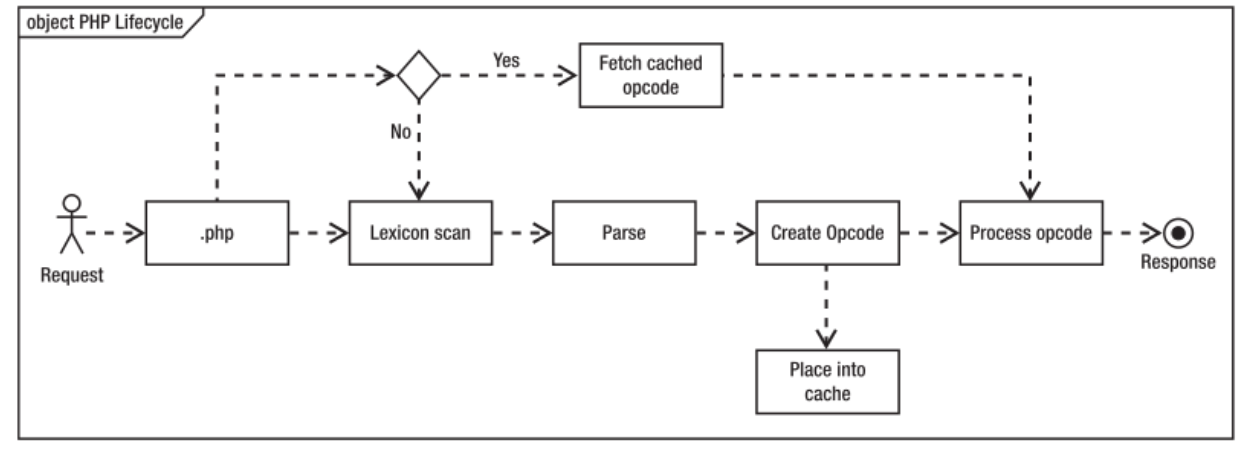
PHP的生命周期可以通过下图展示:

Zend引擎必须从文件系统读取文件、扫描其词典和表达式、解析文件、创建要执行的Opcode,最后执行Opcode。
每一次请求PHP脚本都会执行一遍以上步骤,如果PHP源代码没有变化,那么Opcode也不会变化,显然没有必要每次都重行生成Opcode,结合在Web中无所不在的缓存机制,我们可以把Opcode缓存下来,以后直接访问缓存的Opcode岂不是更快,启用Opcode缓存之后的流程图如下所示:
有一些优秀的opcode缓存器扩展,比如PHP可以选择APC、eAccelerator、XCache等。它们都可以将opcode缓存到共享内存中,而你几乎不需要修改任何代码。
下面是使用APC扩展前后的压测对比:
ab -n 1000 -c 10 http://localhost/upload/index.php\?m\=medal
Concurrency Level: 20
Time taken for tests: 43.814396 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 14933576 bytes
HTML transferred: 14387000 bytes
Requests per second: 22.82 [#/sec] (mean)
Time per request: 876.288 [ms] (mean)
Time per request: 43.814 [ms] (mean, across all concurrent requests)
Transfer rate: 332.84 [Kbytes/sec] received
开启opcode cache缓存后:
Concurrency Level: 10
Time taken for tests: 12.394085 seconds
Complete requests: 1000
Failed requests: 0
Write errors: 0
Total transferred: 15586000 bytes
HTML transferred: 15241000 bytes
Requests per second: 80.68 [#/sec] (mean)
Time per request: 123.941 [ms] (mean)
Time per request: 12.394 [ms] (mean, across all concurrent requests)
Transfer rate: 1228.01 [Kbytes/sec] received
可以看到吞吐量有一定的提升,但是感觉提升不是很大,因为并不是所有的动态内容都在应用了opcode cache之后有了大幅度的性能提升,因为opcode cache的目的是减少CPU和内存的开销,如果动态内容的性能瓶颈不在于CPU和内存,而是I/O操作,那opcode cache的提升是非常有限的。
解释器扩展——脚本跟踪与分析
动态内容在计算过程中,还有很多开销是无法通过opcode 缓存来避免的。我们也需要知道主要的时间消耗,我们有时候需要了解究竟开销来自于脚本程序本身还是其他的外部原因。
Xdebug是一个PHP的PECL扩展,它提供了一组用于代码跟踪和调试的API。能够进行脚本信息上下文收集,函数栈跟踪,错误信息收集等。
下图展示了PHP脚本跟踪扩展的细节:
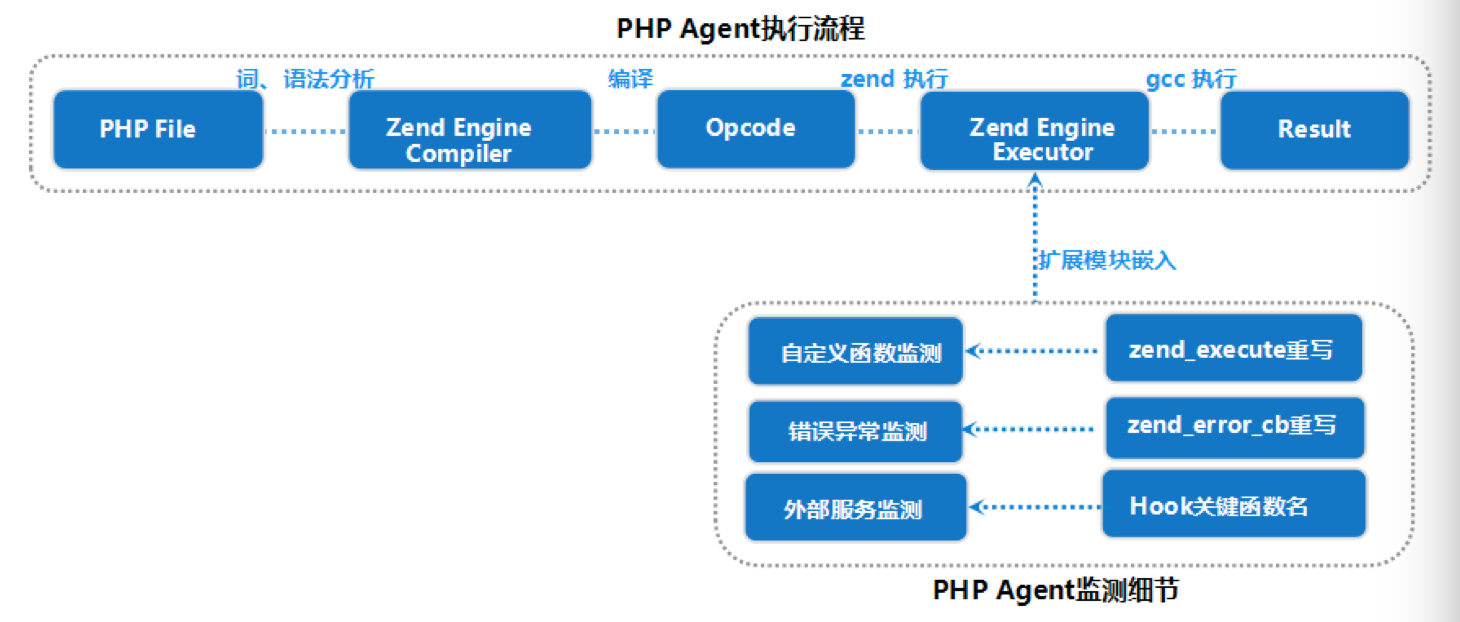
目前对于服务器应用程序的监测(Application Performance Monitor, APM)也是很多公司在做的,比如听云、OneAPM、Mmtrix等(笔者之前参与过关于PHP的探针研发)。相对于开源的Xdebug跟踪,这些产品化的APM有自身的优势:
- 全面的监控数据
PHP监测能够对脚本运行中的各项性能数据进行智能采集、多维度分析。从服务器本身的系统资源(CPU、内存、网络IO等),到PHP运行中的数据收集(函数堆栈、数据库、错误、异常、外部服务等),都能给出全面的监测结果。给用户提供每项性能数据。
- 定制化的监测需求
除了全面的监测功能(函数调用堆栈、错误异常监控、系统资源监控)。PHP监测根据用户自身需求,提供了对应的配置文件,用户可以根据自身应用特点及需求,定制化性能数据的上报、告警。
- 完善的告警机制
告警是监测中相当重要的环节。PHP监测提供较为完善的告警机制(自定义告警策略、多样化告警渠道等),用户能够及时根据告警信息,定位问题。
参考阅读
《构建高性能web站点》 Ch5 动态脚本加速